基于Puppeteer、RabbitMQ與Node.js的PDF批量加工服務(wù)架構(gòu)設(shè)計與落地實踐
背景與需求
在數(shù)字內(nèi)容制作服務(wù)領(lǐng)域,PDF文檔的批量生成與加工是一項常見且需求頻繁的任務(wù)。無論是電商平臺的商品詳情頁導(dǎo)出、企業(yè)內(nèi)部的報表自動化生成,還是在線教育機構(gòu)的學(xué)習(xí)資料打包,都需要高效、穩(wěn)定且可擴展的PDF處理服務(wù)。傳統(tǒng)的手動或單機處理方式不僅效率低下,且難以應(yīng)對高并發(fā)、大規(guī)模的處理需求。為此,我們設(shè)計并落地了一套基于Puppeteer、RabbitMQ與Node.js的分布式PDF批量加工服務(wù)架構(gòu)。
技術(shù)選型與核心組件
- Node.js:作為主要運行時環(huán)境,其非阻塞I/O和事件驅(qū)動特性非常適合處理高并發(fā)的I/O密集型任務(wù),如PDF生成中的網(wǎng)絡(luò)請求、文件讀寫等。
- Puppeteer:一個由Google Chrome團隊維護的Node庫,提供高級API通過DevTools協(xié)議控制Headless Chrome。它是本架構(gòu)的核心,負責(zé)將HTML內(nèi)容(包括復(fù)雜CSS、JavaScript渲染結(jié)果)精準地轉(zhuǎn)換為PDF文檔,支持頁眉頁腳、水印、分頁等高級功能。
- RabbitMQ:作為消息代理(Message Broker),實現(xiàn)任務(wù)的異步處理與解耦。它負責(zé)接收PDF生成任務(wù),并將其可靠地分發(fā)給后端的多個Worker進行處理,保障任務(wù)不丟失,并實現(xiàn)負載均衡。
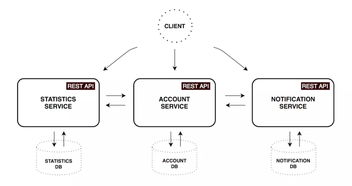
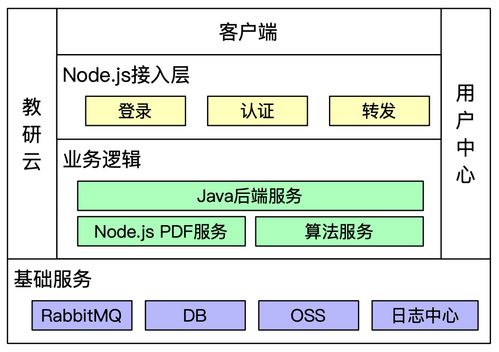
系統(tǒng)架構(gòu)設(shè)計
整個系統(tǒng)采用“生產(chǎn)者-消費者”模型,分為以下幾個核心模塊:
1. 任務(wù)接收與調(diào)度層(API Gateway/Producer)
- 提供RESTful API接口,接收外部系統(tǒng)提交的PDF生成請求。請求中通常包含HTML內(nèi)容、PDF配置參數(shù)(如尺寸、邊距)等。
- 對請求進行基礎(chǔ)驗證與格式化后,將任務(wù)信息封裝為消息,發(fā)送至RabbitMQ的指定任務(wù)隊列。每個任務(wù)分配唯一ID,便于后續(xù)狀態(tài)追蹤。
- 此層為無狀態(tài)服務(wù),可水平擴展以應(yīng)對高并發(fā)請求。
2. 消息隊列層(RabbitMQ)
- 使用工作隊列(Work Queue)模式。創(chuàng)建一個或多個持久化的隊列,用于存儲待處理的PDF任務(wù)消息,確保服務(wù)器重啟后任務(wù)不丟失。
- 可以配置多個隊列以實現(xiàn)優(yōu)先級處理(如VIP用戶任務(wù)進入高優(yōu)先級隊列)。
- 消息確認(Ack)機制確保任務(wù)被Worker成功處理后才會從隊列中移除,防止任務(wù)丟失。
3. 任務(wù)處理層(Worker/Consumer)
- 由多個獨立的Node.js進程(Worker)組成,每個進程都是一個消費者,從RabbitMQ隊列中拉取任務(wù)。
* Worker核心邏輯:
a. 從消息中解析出HTML內(nèi)容和配置。
b. 啟動(或復(fù)用)一個Puppeteer實例,打開一個空白頁。
c. 將HTML內(nèi)容注入頁面,等待必要的資源加載和腳本執(zhí)行(可使用page.waitForNetworkIdle或page.waitForSelector)。
d. 調(diào)用page.pdf()方法,根據(jù)配置生成PDF Buffer。
e. 將生成的PDF上傳至持久化存儲(如AWS S3、阿里云OSS或服務(wù)器本地磁盤),并獲取文件訪問URL。
f. 將任務(wù)ID、狀態(tài)(成功/失敗)、PDF URL或錯誤信息更新至數(shù)據(jù)庫(如MongoDB、Redis)。
g. 向RabbitMQ發(fā)送任務(wù)完成確認(Ack)。
- Worker可以水平擴展,通過增加實例數(shù)量來提升整體處理能力。
4. 狀態(tài)查詢與結(jié)果返回層
- 提供獨立的API,供客戶端根據(jù)任務(wù)ID輪詢或通過WebHook回調(diào)通知,獲取任務(wù)處理狀態(tài)(處理中、成功、失敗)及結(jié)果(PDF文件URL)。
- 狀態(tài)信息通常存儲在Redis或數(shù)據(jù)庫中,保證查詢效率。
5. 存儲與緩存層
- 對象存儲:用于保存最終生成的PDF文件,推薦使用云服務(wù)(S3、OSS)以獲得高可靠性和可擴展性。
- 數(shù)據(jù)庫/緩存:記錄任務(wù)元數(shù)據(jù)、狀態(tài)及結(jié)果索引,用于狀態(tài)查詢和系統(tǒng)監(jiān)控。
關(guān)鍵優(yōu)化與落地實踐
- Puppeteer實例管理:頻繁啟動關(guān)閉瀏覽器實例開銷巨大。采用瀏覽器實例池進行復(fù)用,每個Worker維護一個可重用的實例池,顯著提升處理速度并降低資源消耗。
- 錯誤處理與重試:在Worker中實現(xiàn)健壯的錯誤捕獲。對于網(wǎng)絡(luò)波動等臨時性錯誤,將任務(wù)重新放回隊列(Nack with requeue)進行重試;對于不可恢復(fù)錯誤(如HTML格式錯誤),則標記任務(wù)失敗并記錄日志。
- 資源隔離與限制:每個Puppeteer任務(wù)消耗一定內(nèi)存和CPU。通過控制Worker并發(fā)處理任務(wù)數(shù)、限制單個Puppeteer頁面的內(nèi)存使用,防止單個任務(wù)拖垮整個服務(wù)。可使用Docker進行容器化部署,便于資源限制和管理。
- 監(jiān)控與告警:對RabbitMQ隊列長度(堆積情況)、Worker處理速度、任務(wù)失敗率等關(guān)鍵指標進行監(jiān)控。隊列積壓過多時觸發(fā)告警,便于及時擴容Worker。
- 部署與伸縮:將API層和Worker層分別容器化。在Kubernetes或云服務(wù)器集群上部署,并配置HPA(Horizontal Pod Autoscaling)或基于隊列長度的自動伸縮策略,實現(xiàn)根據(jù)負載動態(tài)調(diào)整Worker數(shù)量。
##
本架構(gòu)結(jié)合了Puppeteer強大的渲染能力、RabbitMQ可靠的消息異步處理能力以及Node.js的高效I/O模型,構(gòu)建了一個高性能、高可靠、可水平擴展的PDF批量加工服務(wù)。它成功地將同步、耗時的PDF生成過程轉(zhuǎn)化為異步、分布式的流水線作業(yè),有效支撐了數(shù)字內(nèi)容制作服務(wù)中大規(guī)模、高并發(fā)的PDF導(dǎo)出需求,提升了系統(tǒng)整體的吞吐量與穩(wěn)定性。該架構(gòu)模式也可被借鑒于其他類似的批量文檔處理、圖片生成等場景。
如若轉(zhuǎn)載,請注明出處:http://m.kadabmusic.com/product/11.html
更新時間:2026-05-18 17:25:49